# 1.背景
Deco 人工干预页面编辑器是 Deco(http://deco.jd.com (opens new window))工作流重要的一环,Deco 编辑器实现对 Deco 智能还原链路 输出的结果进行可视化编排,在 Deco 编辑器中修改智能还原输出的 Schema ,最后改造后的 Schema 经过 DSL 处理之后下载目标代码。
为了赋能业务,打造智能代码生态,Deco 编辑器除了满足通用的静态代码下载场景,还需要针对不同的业务方做个性化定制开发,这就必须让 Deco 编辑器架构设计更加开放,同时在开发层面需要能满足二次开发的场景。
基于上述背景,在进行编辑器的架构设计时主要追求以下几个目标:
- 编辑器界面可配置,可实现定制化开发;
- 实现第三方组件实时更新渲染;
- 数据、状态与视图解耦,模块之间高内聚低耦合;
# 2.业务逻辑
# 2.1 业务逻辑分析
Deco 工作流中贯穿始终的是 D2C Schema ,Deco 编辑器的主要工作就是解析 Schema 生成布局并操作 Schema ,最后再通过 Schema 来生成代码。
入参:已语义化处理之后的 schema json 数据
出参:经过人工干预之后的 schema json 数据

相关 Schema 的介绍可以查看凹凸技术揭秘·Deco 智能代码·开启产研效率革命 (opens new window)。
# 2.2 业务架构分析
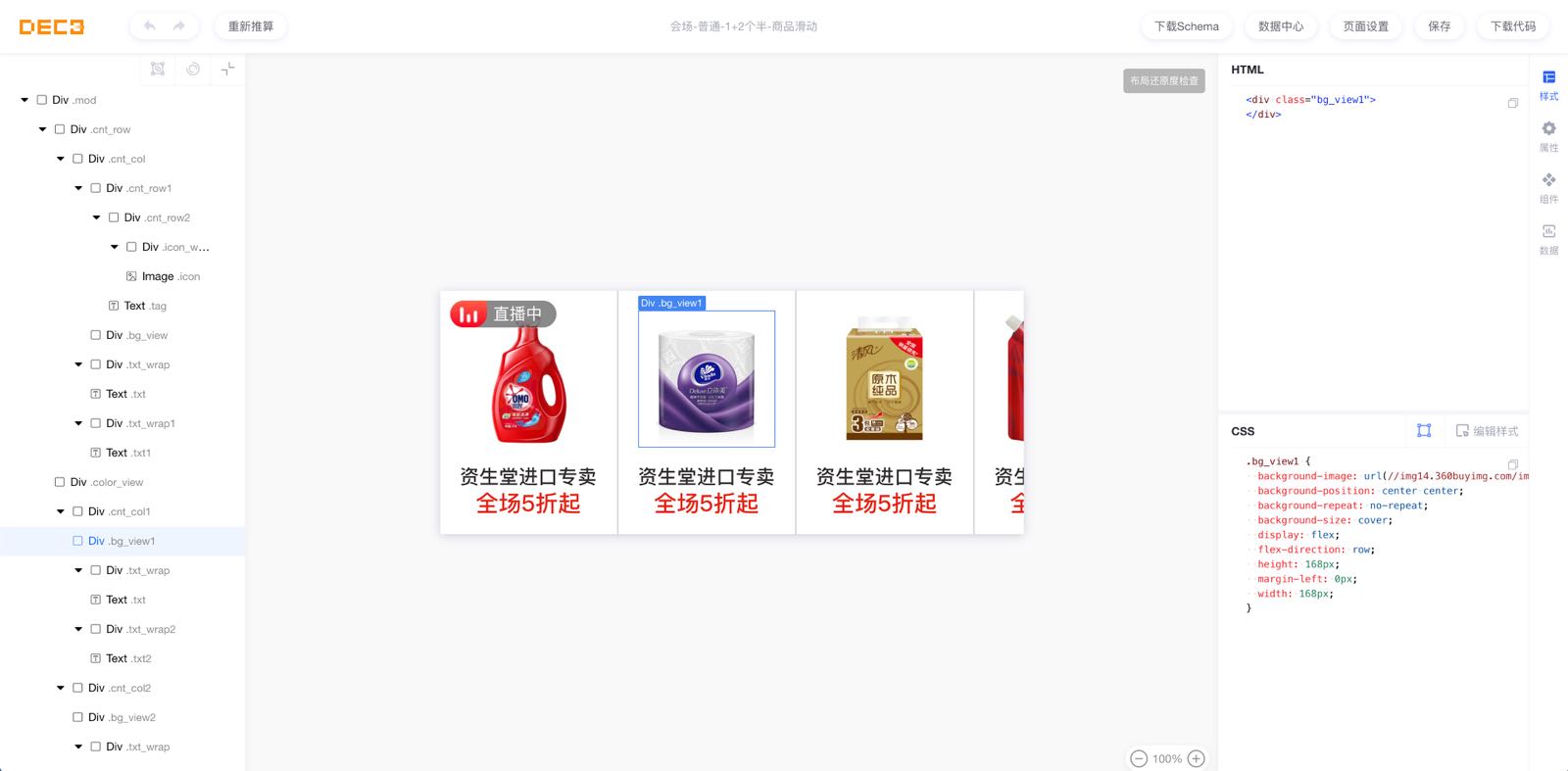
Deco 编辑器主要由 导航状态栏、节点树、渲染画布、样式/属性编辑面板、面板控制栏等组成。
核心流程是对 schema 的处理过程,所以核心模块是节点树 + 渲染画布 + 样式/属性编辑面板。
节点树、样式/属性编辑面板属于较为独立的模块(业务逻辑掺杂较少,大部分是交互逻辑),可单独作为独立的模块开发。画布部分涉及布局渲染逻辑,可作为核心模块开发,导航状态以及面板控制都需要作为核心模块处理。
业务分析完成之后,我们对编辑器有了一个业务模型的初认识,选择一个合适的技术方案来实现这样的业务模型至关重要。
# 3.技术方案设计参考
# 3.1 system.js + single-spa 微前端框架
基于以上前端业务架构分析,在进行技术方案设计的时候,不难第一时间想到微前端的方案。
将编辑器中各个业务模块拆分成各个微应用,使用 single-spa (opens new window) 在工作台的集成环境中管理各个微应用。有以下特点:
- 在无需刷新的情况下,同一个页面可运行不同框架的应用;
- 基于不同框架实现的前端应用可以独立部署;
- 支持应用内脚本懒加载;
缺点:
- 应用和应用之间状态管理困难,需要自己实现一个状态管理机制;
Deco 编辑器暂无多应用需求。契合指数:★★
# 3.2 Angular
Angular (opens new window) 是一个成熟的前端框架,具有组件模块管理,有以下特点:
- 内置 module 管理功能,可将不同功能模块打包成一个 module;
- 内置依赖注入功能,将功能模块注入到应用中;
缺点:
- 学习曲线陡峭,对新加入项目的同学不友好;
- 加载第三方组件较复杂;
契合指数:★★★
# 3.3 React + theia widget + inversify.js
使用 inversify 这个依赖注入框架来对不同的 React Widget (opens new window) 进行注入,同时每个 Widget 可独立发包。
Widget 的编写方法参考 theia browser widget 写法,有以下特点:
- Widget 代表一个功能模块,如属性编辑模块、样式编辑模块;
- Widget 有自己的生命周期,比如在装载和卸载时有相应钩子处理方法;
- 通过 WidgetManager 统一管理所有 Widget;
- Widget 相互独立,扩展性强;
缺点:
- 和传统组件搭建方式区别比较大,有一定挑战性;
- API 多且复杂,不易上手;
契合指数:★★★★
# 3.4 React + inversify.js + mobx + 全局插件化组件加载
使用 inversify 来对不同的插件化组件进行注入,每个插件化组件独立发包,同时使用 mobx 来管理全局状态以及状态分发。
使用插件化组件具有以下特点:
- 插件化组件独立开发,可以通过配置文件异步加载到全局并渲染;
- 插件化组件可共享全局 mobx 状态,通过 observer 自动更新;
- 通过 Module Registry 注册插件,统一管理插件加载;
- 天然契合外部业务组件加载以及渲染方式;
缺点:
- 插件开发模式较复杂,需要起不同的服务。
契合指数:★★★★★
基于以上技术方案设计与参考,最终确定了全局插件化组件方案,总体的技术栈如下:
| 描述 | 名称 | 特性 |
|---|---|---|
| 前端渲染 | React | 目前支持动态加载模块 |
| 模块管理 | inversify.js | 依赖注入,独立模块可注入各类 Service |
| 状态管理 | mobx.js | 可观察对象自动绑定组件更新 |
| 样式处理 | postcss/sass | 原生 css 预处理 |
| 包管理 | lerna | 轻松搞定monorepo |
| 开发工具 | vite | 基于 ES6 Module 加载模块,极速HMR |
思路:
- 搭建核心组件模块与面板控制大体框架,独立模块可动态注入并渲染
- 异步拉取模块配置文件,通过配置渲染面板,并动态加载面板内容
- 独立模块单独开发,使用 lerna 管理
- 业务组件(大促/夸克)皆可作为独立模块加载
- 使用依赖注入管理各个业务模块,使得数据、状态与视图解耦
# 4.技术架构设计
基于以上确定的技术方案以及思路,将编辑器技术架构主要分为一下几个模块:
- ModuleRegistry
- HistoryManager
- DataCenter
- CoreStore
- UserStore
使用 inversify.js 进行模块依赖管理,通过挂载在 window 下的 Container 统一管理:

Container 是一个管理各个类实例的容器,在 Container 中获取类实例可通过 Container.get() 方法获取。
通过 inversify.js 依赖注入的特性,我们将 HistoryManager、DataCenter 注入到 CoreStore 中,同时模块注册时使用单例模式,CoreStore 中或 Container 中引用的 HistoryManager 和 DataCenter 就会指向同一个实例,这对于整个应用的状态一致性提供了保证。
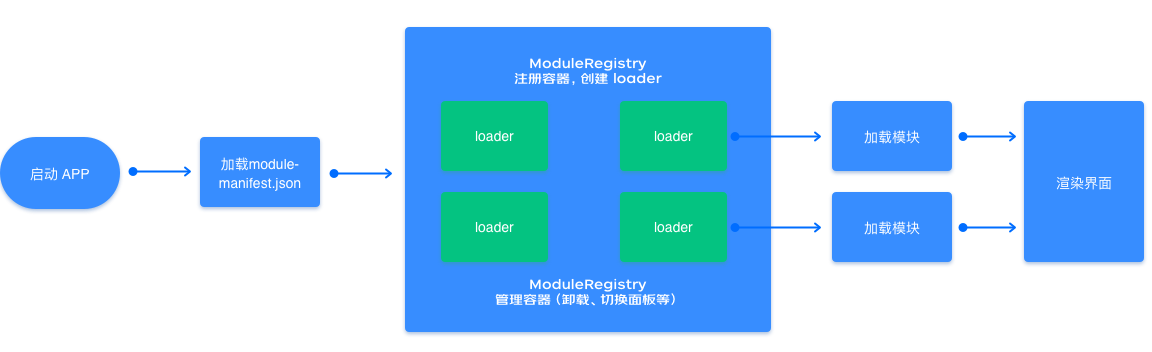
# 4.1 ModuleRegistry
ModuleRegistry 是用来注册编辑器中各个容器,Nav、Panels等等,它的主要工作是用来管理容器(加载、卸载、切换面板等)。
工作台主要分为 Nav 容器、Left 容器、Main 容器、Panels 容器:

每个容器分别承载对应的前端模块,我们设计了一个模块配置文件module-manifest.json,用于每个容器内加载对应的 js 模块文件:
{
"version": "0.0.1",
"name": "deco.workbench",
"modules": {
"nav": {
"version": "0.0.1",
"key": "deco.workbench.nav",
"files": {
"js": [
"http://dev.jd.com:3000/nav/dist/nav.umd.js"
],
"css": [
"http://dev.jd.com:3000/nav/dist/style.css"
]
},
},
"left": {
"version": "0.0.1",
"key": "deco.workbench.layoute-tree",
"files": {
"js": [
"http://dev.jd.com:3000/layout-tree/dist/layout-tree.umd.js"
],
"css": [
"http://dev.jd.com:3000/layout-tree/dist/style.css"
]
}
}
}
}
ModuleRegistry 处理流程如下:
# 4.2 CoreStore
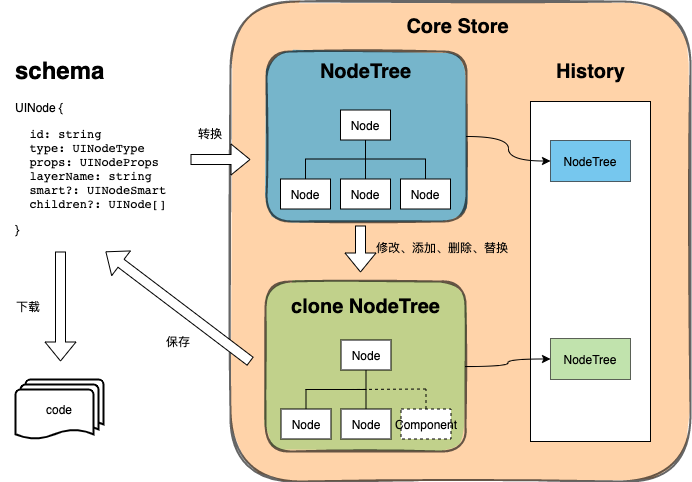
CoreStore 用来管理整个应用的状态,包括 NodeTree 、History(历史记录)等。它的主要业务逻辑分为以下几点:
- 获取 D2C Schema
- 将 Schema 转换成 Node 结构树
- 通过修改、添加、删除、替换等操作生成新的 Node 结构树
- 将最新的 Node 结构树推入到 CoreStore 里注入进来的 History 实例
- 保存 Node 结构树生成新的 D2C Schema
- 获取最新的 D2C Schema 下载代码
CoreStore 从 Container 中注入了 HistoryManager 以及 DataCenter 的实例,大致的使用方式是:
import { injectable, inject } from 'inversify'
import { Context, ContextData } from './context'
import { HistoryManager } from './history'
import { Schema, TYPE } from '../types'
type HistoryData = {
nodeTree: Schema,
context: ContextData
}
@injectable() // 声明可注入模块
class Store {
/**
* 历史记录
*/
private history: HistoryManager<HistoryData>
/**
* 上下文数据(数据中心)
*/
private context: Context
constructor (
// 依赖注入
@inject(TYPE.HISTORY_MANAGER) history: HistoryManager<HistoryData>,
@inject(TYPE.DATA_CONTEXT) context: Context
) {
this.history = history
this.context = context
}
}
在以上代码块中,历史记录以及数据中心均作为独立的模块被注入到 CoreStore 中,这里对相应实例的修改会影响到 Container 下的实例对象,因为它们都指向同一个实例。
# 4.3 HistoryManager
HistoryManager 主要是用来管理用户操作历史记录信息,基于依赖注入特性,它可以直接注入到 CoreStore 中使用,并且也可以通过 Container.get() 方法获取到最新的实例。
HistoryManager 是一个双向链表结构的抽象类,通过保存数据快照到每一个链表节点上,方便且快捷地穿梭历史记录。与普通双向链表略有不同的地方是,当 History 链表中插入一个节点时,前面的链表节点会重新链出一个新的分支。
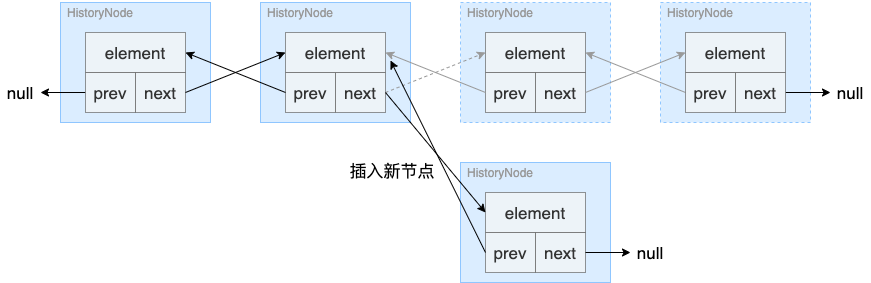
# 4.4 DataCenter
数据中心是整个 Deco 编辑器用来管理楼层数据的一个独立模块,它一开始只用来服务于编辑器本身的应用开发,后来为了方便用户在编辑器应用里调试,数据中心正式以一个功能的方式沉淀了下来。
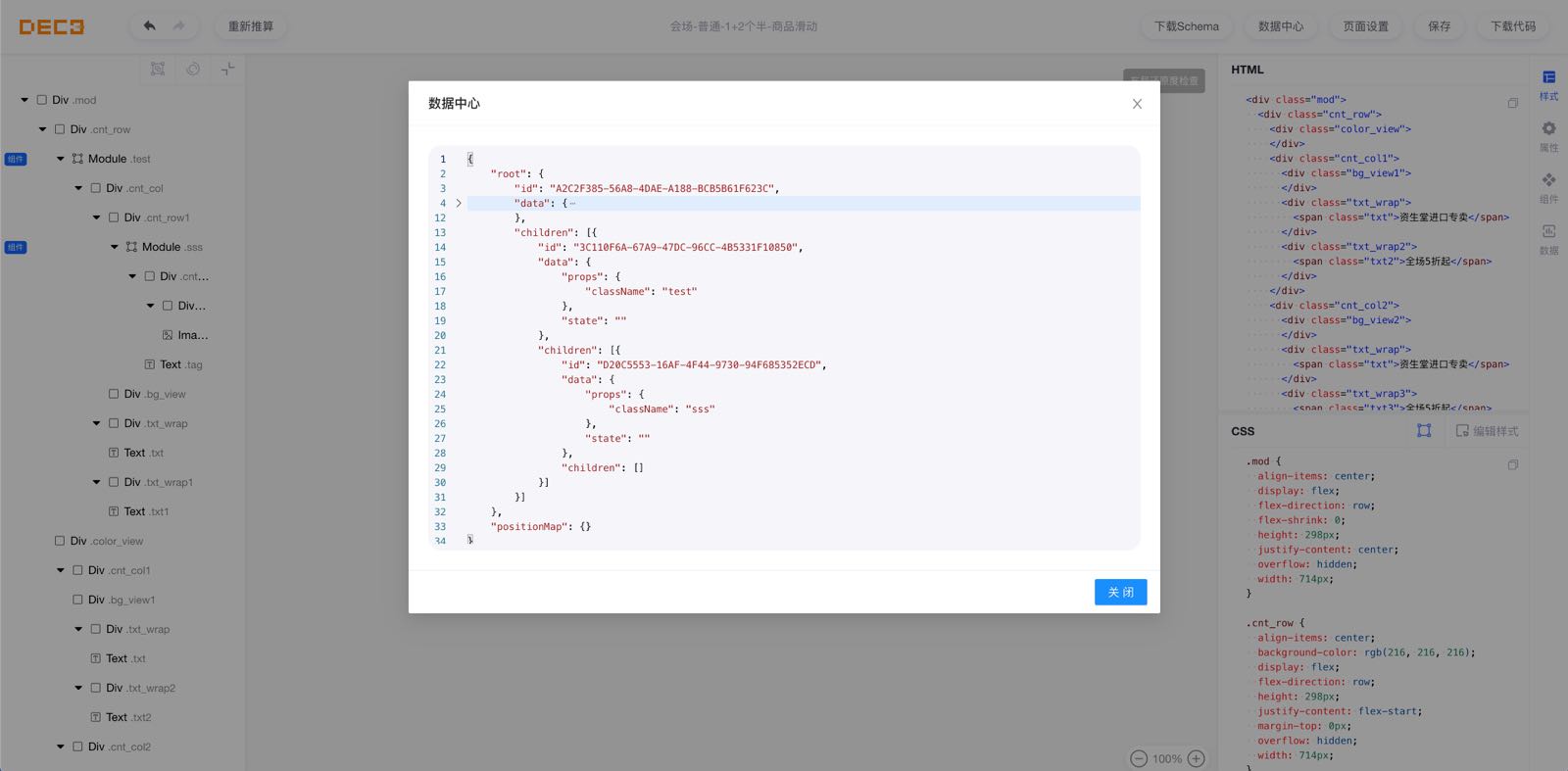
楼层数据是页面节点在进行数据绑定时所用的真实数据,通过当前节点的数据上下文获取。如果将这些真实数据绑定在原有的 NodeTree 上,那我们的 NodeTree 将是一个存储了所有信息的节点树,逻辑相当复杂并且冗余,同时在做 Schema 同步时也是一个无比困难的任务。因此,我们考虑将楼层数据单独抽出来一个模块进行管理。
如下图,ContextTree 是数据上下文的数据节点树,它和 NodeTree 上的节点一一对应绑定,并且通过位置信息(如 0-0,代表根节点的第一个子节点)绑定在一起,与 NodeTree 不同的是,它是一个具有空间关系的节点树,如位置 0-2 的节点需要插入一个上下文节点的话,需要将位置为 0-2 的 context 节点插入到位置为 0 的子节点中去,同时将位置为 0-2-0 的 context 节点设为 0-2 节点的子节点。同理,若将 0-2 节点从 ContextTree 中删掉,则需要将 0-2 节点从 0 节点子节点中删掉,并且把 0-2-0 节点设为 0 节点的子节点。
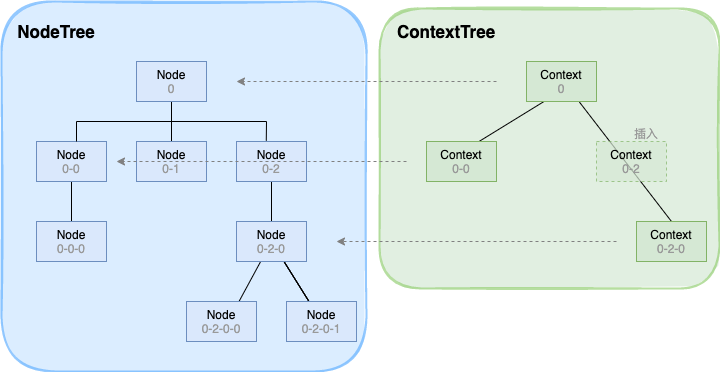
这样,便将管理数据的模块从 NodeTree 中抽离了出来,DataCenter 独立管理该页面的数据上下文,这样不仅使得我们在代码层面做到更加解耦,同时沉淀出了“数据中心”这个功能模块,方便用户在数据绑定时进行调试工作。
# 5 技术难点
# 5.1 模块管理
# 5.1.1 inversify
通过以上的架构分析,我们不难看出,虽然 Deco 编辑器主要业务功能逻辑较为简单,但是其中各个模块相互独立且相互配合,合作完成编辑器应用的数据、状态、历史以及渲染更新的操作,如果只是简单通过 ES6 Module 的模块管理是远远不够的。由此我们引入了 inversify.js 进行模块的依赖注入管理。
inversify 是一个 IoC(Inversion of Control,控制反转)库,它是 AOP(Aspect Oriented Programming,面向切面编程)的一个 JavaScript 实现。
编辑器使用 “Singleton” 单例模式,每次从容器中获取类的时候都是同一个实例。不管是从类中的依赖获得实例还是从全局 Container 中获得实例都是同一个,这样的特性为整个编辑器应用状态的一致性提供了有力的保证。AOP 天然的优势就是模块解耦,它使得编辑器应用的扩展性得到了一定程度的提高。
更多关于 AOP 与 IoC 的介绍可参考文章羚珑 SNS 服务 AOP 与 IoC 的实践 (opens new window)。
# 5.1.2 mobx
得益于 mobx 观察者模式的状态更新机制,使得状态管理与视图更新更加解耦,为编辑器的状态维护和模块管理提供了很大的便利。不同的数据状态(如 AppStore 与 UserStore)之间互相独立并且互不干扰。
# 5.2 页面节点树的查找与更新
页面节点树(NodeTree)是一个针对 Schema 设计的抽象树,它的主要功能是对页面节点进行增删改查等操作,同时它还映射到渲染模块进行页面画布的更新渲染,最后通过一个转化方法再转为 Schema 。
NodeTree 是页面节点的抽象表现,当页面设计稿比较大(比如大促设计稿)的情况下,节点树也是一颗相当庞大的抽象树,在对节点进行查找的时候,如果通过简单的深度遍历算法进行查找将有巨大的性能损耗。针对这种情况,我们通过拿到每个节点的位置信息(如0-0)进行索引匹配查找,这样基本实现了无伤查找。另外,基于 React 更新的机制,NodeTree 节点添加或删除之后,索引自动更新,省去了手动更新位置信息的麻烦。
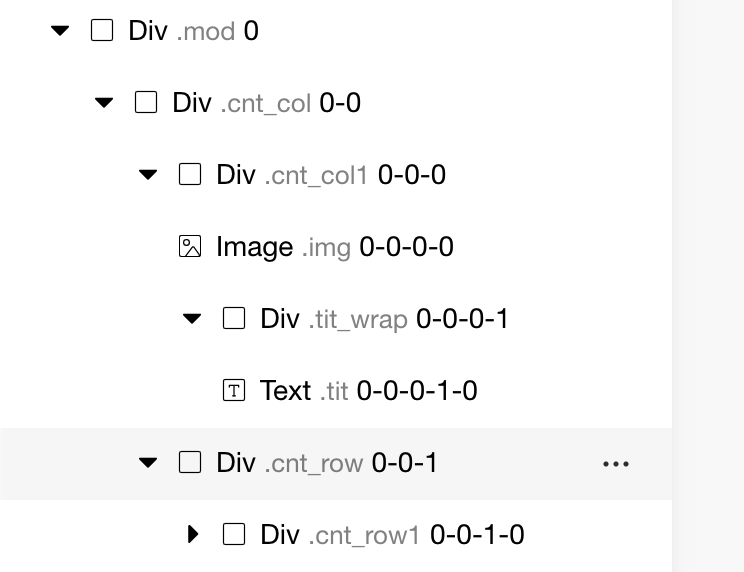
同时,也是基于节点位置信息的设计,实现了前面介绍的数据上下文节点的空间信息维护。
# 5.3 第三方组件的加载与渲染
在 Deco智慧代码618应用 (opens new window)中有提到 Deco 组件识别工作的流程,在 Deco 中,一份组件样本(视图)对应一个组件配置,基于组件配置的多样性,一个组件可能有多个样本。对于编辑器来说,组件识别服务返回的相似组件推荐其实就是返回了组件的属性配置信息,编辑器只要找到对应的样本组件配置信息,就可以进行相应的替换工作。那么,第三方组件是如何加载的呢?
在文章的开头,我们便介绍了插件化开发模式,对于 Deco 编辑器来说,第三方组件也是一个插件,所以只需要将第三方组件库打包成一个 UMD 格式的 JavaScript 文件,并且在 module-manifest.json 文件中配置 deps 插件信息即可,这样第三方组件便以插件的形式被加载到了编辑器的全局环境中去。
同时,编辑器存储了一份第三方组件的配置表,在用户进行相似组件替换时,通过该配置表获取对应样本的配置信息给到编辑器的画布模块进行渲染。这里默认规定第三方组件使用 React 开发,编辑器在渲染的时候使用 React.createElement 原生方法进行组件渲染。
// 组件配置信息数据结构
export interface AtomComponent {
id: string
componentName: string
logicHoc: string
type: string
image: string
name: string
props: any
pkg: string
tableName: string
value?: string | number
children?: (Partial<AtomComponent> | string)[] | string
propsComponent?: Partial<AtomComponent>[]
}
目前,这份配置表是打包在代码里面的,在编辑器未来的版本中,将会把这份配置表和 Deco 开放平台相融合,开放给用户编辑,编辑器在进行初始化加载时会以第三方配置的方式加载进来。
# 6 最后
目前 Deco 已经支持了 618 、11.11 等背景下的大促会场开发,并且打通了内部低代码平台一键进行代码构建和页面预览,通过 Deco 搭建的数十个楼层成功上线,效率提升达到 48%。
Deco 智能代码项目是凹凸实验室在「前端智能化」方向上的探索,我们尝试从设计稿生成代码(DesignToCode)这个切入点入手,对现有的设计到研发这一环节进行能力补全,进而提升产研效率。其中使用到不少算法能力和AI能力来实现设计稿的解析与识别,感兴趣的童鞋欢迎关注我们的账号「凹凸实验室」(知乎 (opens new window)、掘金 (opens new window))。
# 7 更多文章
设计稿一键生成代码,研发智能化探索与实践 (opens new window)